|
|
 发表于 2020-8-1 19:26:41
|
发表于 2020-8-1 19:26:41
|
查看: 7512 |
回复: 0
网络逆向(一) 油猴脚本与抓包初步 以显示b站楼层编号为例
本文为看雪论坛优秀文章
看雪论坛作者ID:devseed
0x0 前言
之前我在写galgame中的逆向系列教程,最近突然想来点新鲜的,试试分析一下网络相关的逆向,想着可以把学习与折腾的心得和体会分享给大家。
网络逆向相比来说比较特殊,虽然js逆向上手后比起x64,arm64等机器码逆向要容易很多,但是依赖于服务器api,有着时效性与不可重复的特点,测试环境和相关的部署对于新手来说也很麻烦,网络协议相关的更是非常繁杂。因此,网络逆向对于新手来说门槛很高。本系列教程将结合几个例子,来谈谈我的理解与想法。同样,此系列教程也在隔壁同步更新,内容完全一样。
大家都熟悉油猴脚本了, 但是可能对于怎么编写可能感觉不太容易上手,本节将以显示b站楼层编号为例,结合简单的抓包,来谈谈如何上手油猴脚本。
需要的工具:
Chrome 调试脚本与网页抓包
Tempormonky 加载js脚本
fiddler 抓包
jQuery 查询dom元素与插入界面
firefox RESTClient, python requests 测试发包
TrustForMe 解决安卓SSL Pinning无法抓HTTPS包问题 本例油猴脚本成品:b站显示楼层编号
0x1 网页获取评论api分析
动机:非常讨厌欢b站取消楼层号,就和写代码没有行号一样,不好定位,看起来非常不爽。
自从b站改版以来,我们发现网页版取消了评论楼层数的显示,但是旧版客户端却还能看到楼层数。因此我们推测有两种可能:
(1)返回的数据里还有楼层编号信息,但是在网页界面隐藏了
(2)采用新的api不再返回楼层编号信息
在评论处ctrl+shift+i跳转到对应html元素,检查后发现没有楼层(floor)相关的信息,因此推测十有八九是新api本身就没有楼层了。
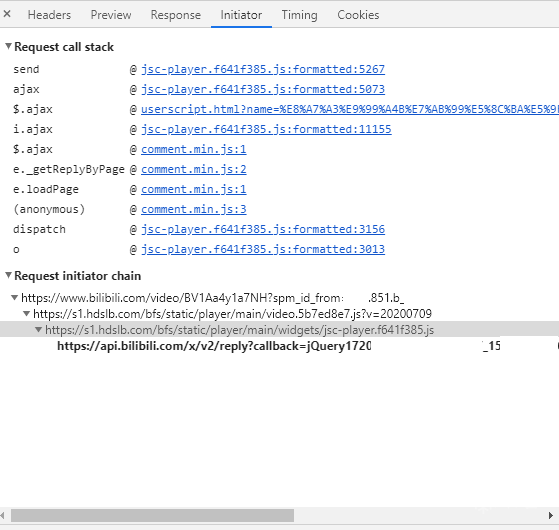
我们用chrome抓包来看看调用了什么api,F12->Network可以抓包,点击initialor可以查看调用关系(callback)。
我们看到获取评论用了GET方法,运用jsonp来进行跨域,我们调用的时候可一把jsonp和callback去掉。简单分析得到如下分析:
url: https://api.bilibili.com/x/v2/reply/
"oid": av号
"pn": 页码
"sort": 0 时间倒序;2 热度倒序
"type": 1 视频
Return: json对象, resp['data']['replies']为评论,里面没有floor参数 0x2 app端获取评论api分析
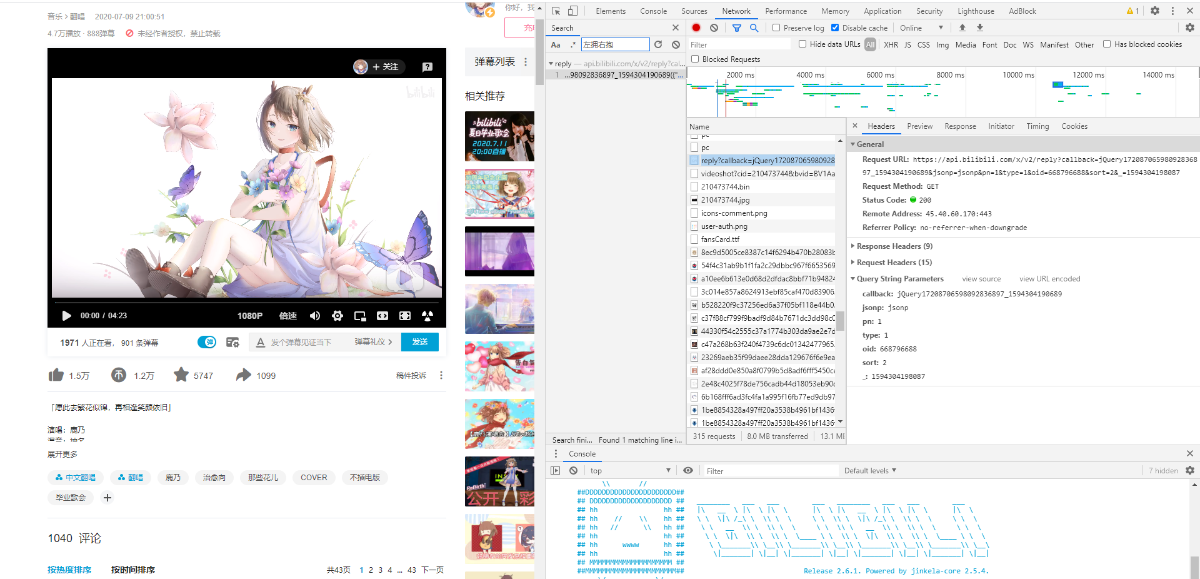
分析安卓版,需要xposed框架,安装TrsutForMe,否则抓不到https包。fiddler抓安卓包步骤为:
1 fiddler Tools Options 设置
HTTPS, 勾选"capture HTTPS", "decrypt https traffic", "Ignore server certificate errors"
Connect 勾选 "Allow remote computer to connect", "resuse client...", "reuse server ..."
fiddler设置完一定要重启fiddler才生效
2 windows防火墙添加fiddler允许
3 手机设置代理为pc的ip,如 http://xxx.xxx.xxx.xxx:8888
并访问此ip下载ca证书
4 xposed just trust me, TrustMeAlready
https的网站使用伪证书可以抓到,而在app里面同样的方法就抓不到用了SSL Pinning,
即SSL证书绑定,是验证服务器身份的一种方式,是在httpst协议建立通信时增加的代码逻辑,
它通过自己的方式验证服务器身份,然后决定通信是否继续下去。它唯一指定了服务器的身份,所以安全性较高。
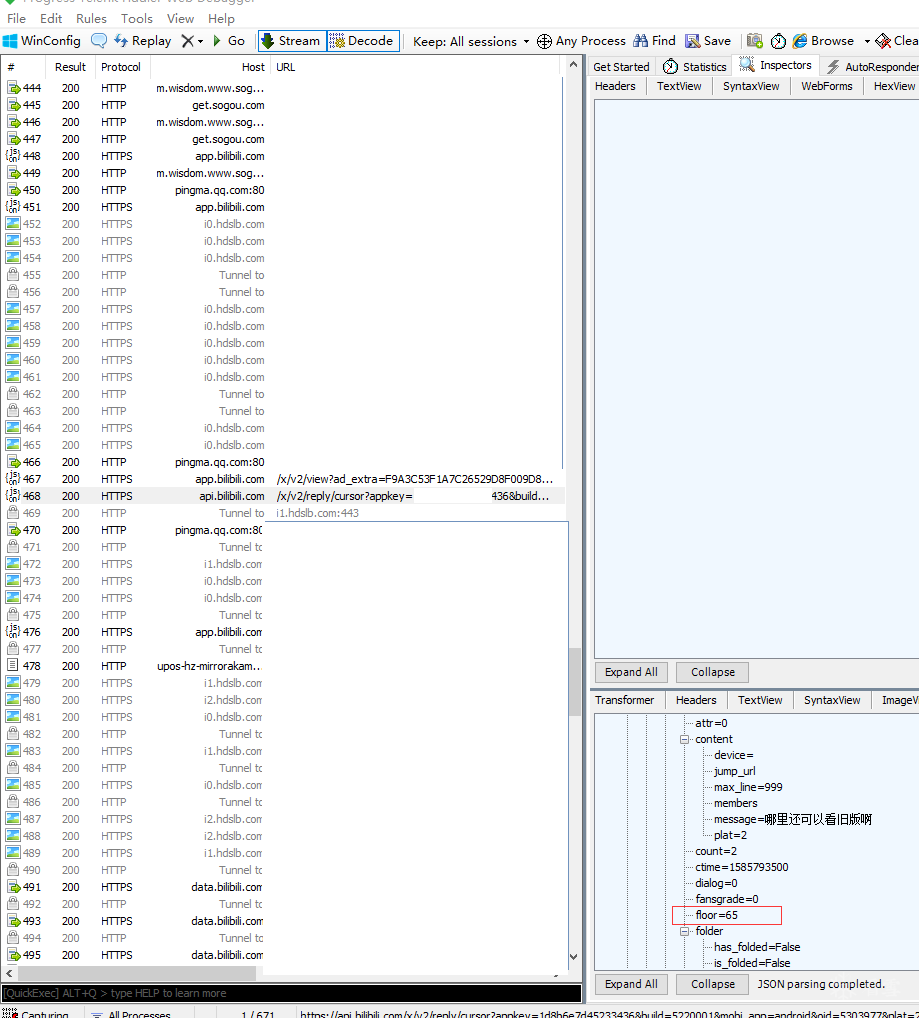
同样也是Get获取,抓包后可以看到app端返回数据有floor,逐个测试去除不需要的参数,同理可以分析出来app端的api:
url: https://api.bilibili.com/x/v2/reply/cursor
"oid" : av号,
"max_id": 最大楼层数
'size': 返回信息条数
"sort": 0 时间倒序;2 热度倒序
"type": 1 视频
Return: json对象, resp['data']['replies']为评论,里面有floor参数
import requests
import json
def replycursor_app(oid, max_id, size=20, sort=0, type=1):
resp = requests.get(url="https://api.bilibili.com/x/v2/reply/cursor",
headers = {
"User-Agent": 'Mozilla/5.0 BiliDroid/5.22.1 (bbcallen@gmail.com)'
},
params = {
"oid" : oid,
"max_id": max_id, #last floor in decrease, if "", from the last
'size': size,
"sort": sort,
"type": type,
# 'plat': 2,
# 'platform': 'android',
# 'mobi_app':' android',
# 'appkey': '',
# 'build': '',
# 'ts': '',
# 'sign': ''
}, verify=False)
return json.loads(resp.content)
对于分析的api用python requests或者firefox RESTClient发包检查一下没问题。
0x3 jQuery从页面元素获取api参数
我们刚才分析完了b站旧版api显示楼层编号api,现在还需要得到api的参数,这些参数往往在html上有体现。
比如说返回值有个rpid,猜测是评论id,这个往往在页面上也有元素来定位,但是属性名不一定一样。我们随便看某条评论,ctrl+shift+i查看html元素,发现属性值data-idj就是rpid。同理也可以把其他参数找出来,这里不再赘述。
获取各参数的jQuery如下:
var url_av = $('meta[property="og:url"]').attr('content');
var oid = url_av.split('/')[4].slice(2);
var pn = $('div#comment div.comment-header span.current').html();
var sort = $('div.tabs-order li.on').attr('data-sort');
0x4 添加评论楼层
相关api我们搞明白了,参数也已经搞清楚了,那么可以写js脚本简单测试一下了。
这时候可以先用chrome的snipplet测试一下,这个调试起来比直接上油猴脚本方便一些,之后再用油猴脚本。
发送请求可以用$.get(url, params, (resp) => {}),注意这个是异步的,可以用async和promise resolve封装一下,更加整洁避免回调地狱。
async function replycursor(oid, pn=1, sort=0) //时间顺序,游标
{
return new Promise(resolve => {
$.get("https://api.bilibili.com/x/v2/reply/cursor", {
"pn" : pn,
"oid":oid,
"type":1, //视频、专栏、话题……
"sort":sort
},
function(resp){
return resolve(resp)
})
})
}
添加文本可以根据resp里面的rpid匹配html中的data-id元素,然后prepend楼层。
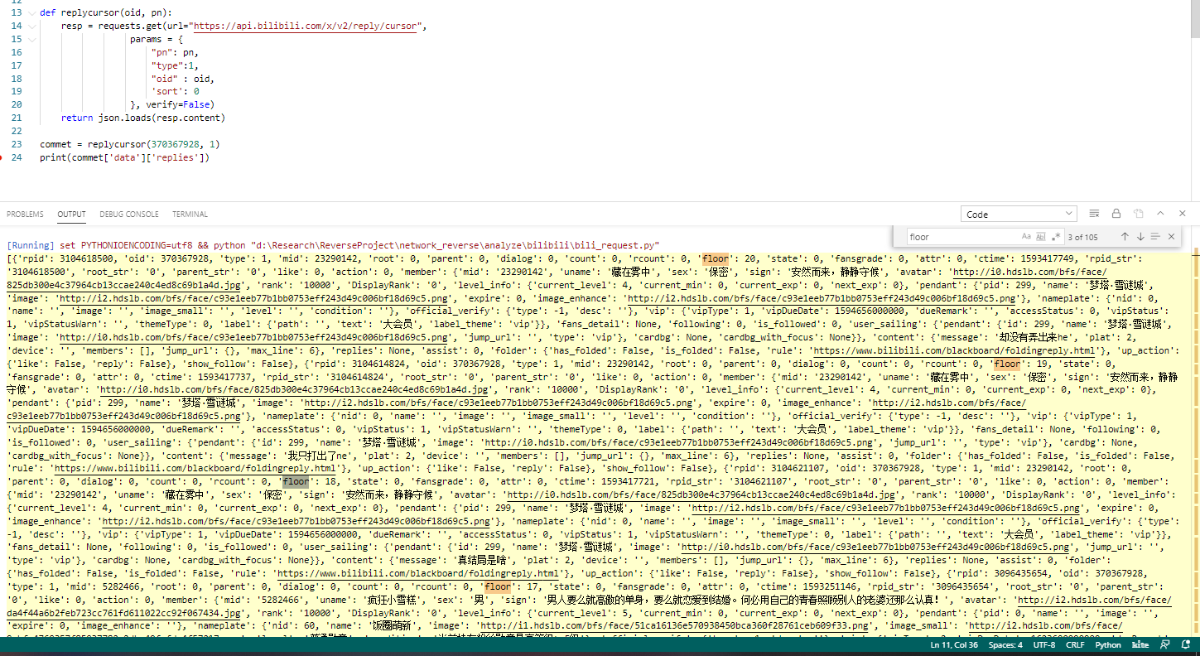
resp = await replycursor_app(oid, pn);
console.log(resp)
var replies = resp['data']['replies']
for (var i in replies) //添加评论
{
let info = $('div.[data-id="'+ replies['rpid'].toString() +'"] div.con div.info');
info.prepend("<span>#"+ replies['floor'].toString() + "</span>");
}
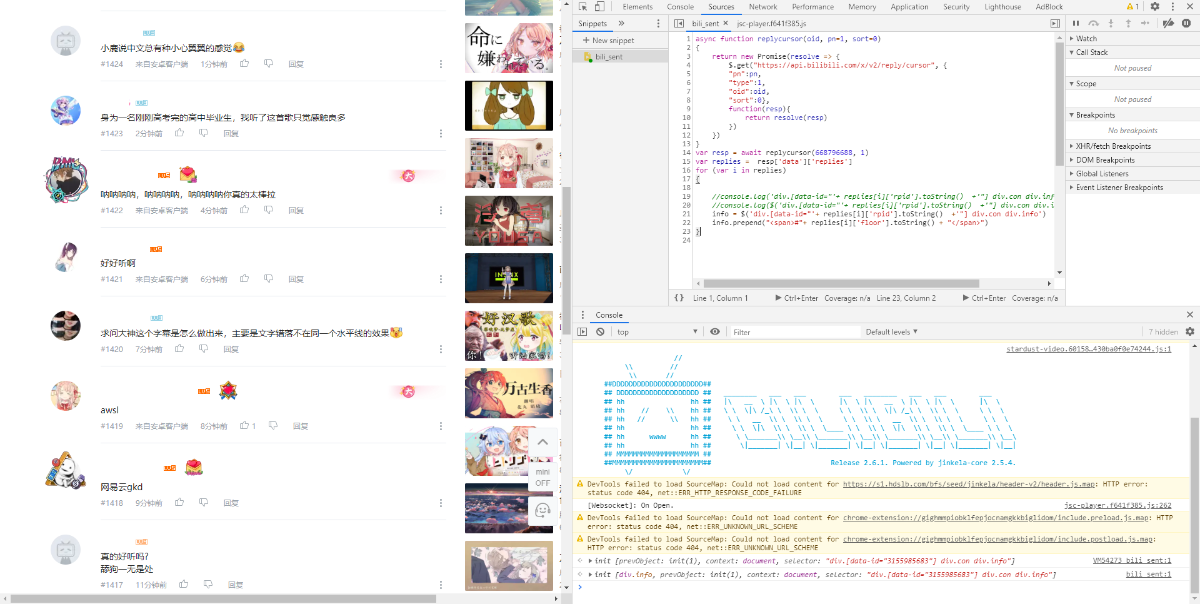
简单测试一下,大概是这种效果, 久违的楼层号终于出现了,太爽了。
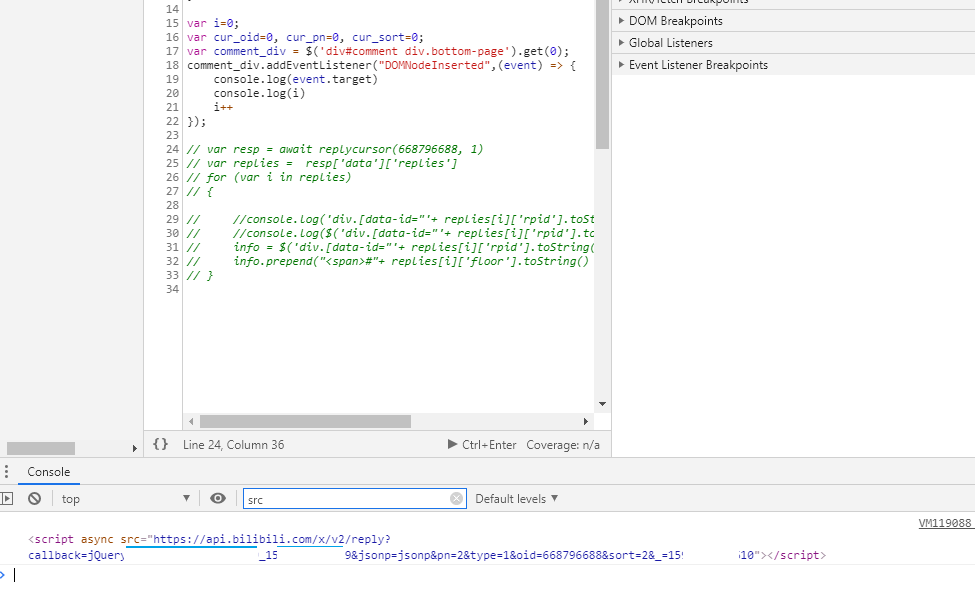
到这里我们已经完成了主要的任务了,但是还有一个问题,我们这个脚本只是运行了一次,那每次切换页面都要手动点击运行,那么有没有办法自动进行呢?答案就是document.addEventListener("DOMNodeInserted",(event) => {}});这个函数。在这个函数的回调函数中可以看到哪些页面变化,变化后的和上一次比较来判断是否切换页面。需要注意的是DOMNodeInserted每个变化都会调用,需要用event.target来筛选。
顺便一提,在监视target中海看到了插入了一条<script async src='...'/>来提交异步加载请求,也可以根据这个来获取api参数。
另外,其实还有些具体问题需要优化,比如说如何知道某一页的max_id值,这些就要参考replay\main和replay\replay\cursor等以前页面api了,但原理都差不多,此处不再追溯。
本节完整代码详见我的油猴脚本:https://greasyfork.org/zh-CN/scr ... i-show-floor-number
0x5 补充
(1) 油猴脚本常用声明项// @name 脚本名
// @name:zh 脚本中文名
// @version 脚本版本
// @description 脚本描述
// @author 作者名
// @match 匹配的网址
// @icon 脚本图标网址
// @grant 脚本权限
// @require 依赖项网址 (2) 注意await异步,等待的时候进程挂起了,之后别的coroutine赋值了全局变量,恢复后可能到读脏数据。(3) 有时候重复向服务器请求次数太多会返回无效数据,改完js脚本可能需要刷新
|
温馨提示:
1.如果您喜欢这篇帖子,请给作者点赞评分,点赞会增加帖子的热度,评分会给作者加学币。(评分不会扣掉您的积分,系统每天都会重置您的评分额度)。
2.回复帖子不仅是对作者的认可,还可以获得学币奖励,请尊重他人的劳动成果,拒绝做伸手党!
3.发广告、灌水回复等违规行为一经发现直接禁言,如果本帖内容涉嫌违规,请点击论坛底部的举报反馈按钮,也可以在【 投诉建议】板块发帖举报。
|





 窥视卡
窥视卡 雷达卡
雷达卡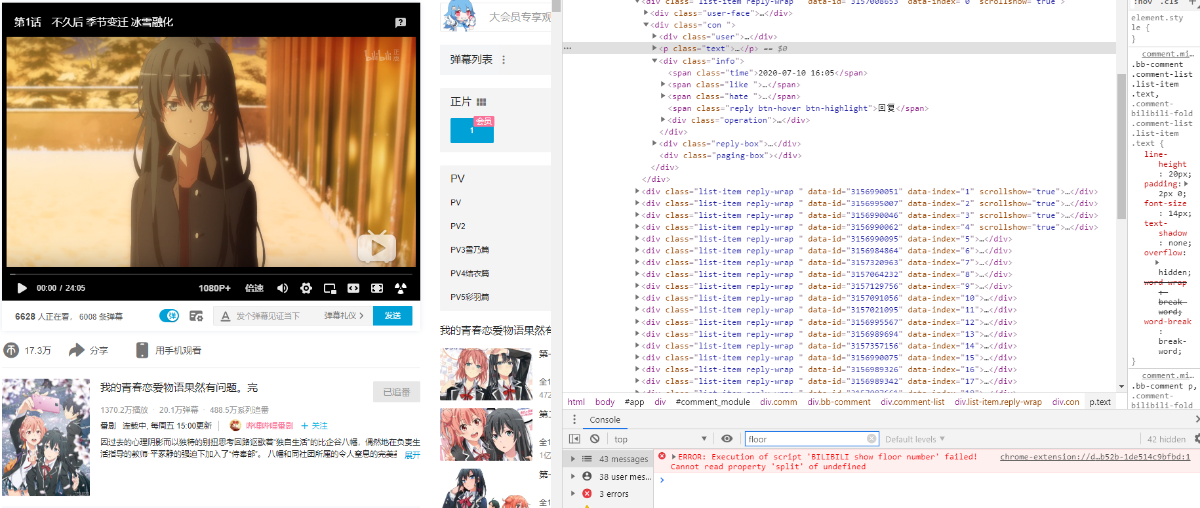


 提升卡
提升卡 置顶卡
置顶卡 关闭卡
关闭卡 开启卡
开启卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜